0 前 言
产品质量是其质量特征满足顾客需求的程度,质量控制就是采取一定的方法使产品的质量特征符合规定的标准或为了达到质量要求所采取的作业技术和活动。长期以来,人们为实现产品质量的自动和准确分析做了大量的研究工作,但实践表明,这一目标并没有全部实现。实际质量的分析,特别是疑难质量的诊断,仍然需要分析专家或通过专家会诊来分析决定。近年来,质量控制技术虽有了较大发展,但仍难以实现自动化的质量控制,特别是深层次的质量分析仍显得无能为力。因此,转变思想,研制开发基于先进技术的质量控制分析系统变得十分迫切。质量控制应贯穿于质量形成的全过程,包括质量检验、设计质量控制、工序质量控制、工作质量控制和供货商质量控制等。因此,质量控制是一个多源的复杂处理过程。基于以上分析,将数据挖掘技术引入质量控制领域,设计了一个基于数据挖掘技术的产品质量控制系统模型, 以解决该领域中的复杂性、继承性,以及质量控制技术向自动化、智能化方向发展所面临的问题。
1 面向质量控制的数据挖掘方法
1.1 计算机辅助质量控制数据仓库、集市模型
质量控制的含义是指达到质量要求所采取的作业技术和活动。质量控制包括对产品质量的监测、检测、处理、评价和纠偏等操作和活动。计算机辅助质量控制,就是利用计算机等智能和自动化技术对产品质量进行检测、分析和控制。现代质量控制包括产品开发决策、设计、制造、销售以至售后服务等全生命周期的各个阶段,其中的质量信息种类繁多、数据量大,如对某型号产品而言,影响该产品总体性能和战术指标的参数就有500多个,零部件上万个,每个零件从设计、加工直至产品检测和使用等需要大量信息,要将其有条不紊、分门别类地管理起来,提高对产品质量数据的使用效率以及为质量决策者提供可靠、正确、科学和有效的决策、评价依据,必须加强研制基于先进数据库技术的质量数据管理系统。事实上,让用户能够访问数据仅仅解决了数据问题的极小部分。数据库生成系统的真正目标是实现决策支持或业务智能,以帮助人们进行更好的、更加智能的决策和评价等。目前数据库生成环境能提供用户对数据访问的能力,但是它并不能解决用户的所有问题。为了解决数据信息的复杂问题,Bill Inmon提出了数据仓库的概念,即数据仓库是面向主题的、集成的、稳定的、不同时间的的数据集合,用于支持经营管理中决策制定过程。
基于数据仓库、集市技术的产品质量控制系统结构框图如图1所示。对于质量信息系统数据仓库而言,优先选择的方法是围绕四个数据存储和三个数据流进行的。数据从源头开始输送到综合层(数据流1),在此得到净化和综合,然后输送到数据集市(数据流2),最后从数据集市通过应用程序输送到最终用户(数据流3)。要使质量系统数据仓库真正有效,首先必须满足能够从各种数据源中抽取数据;其次能将数据综合到数据仓库中进行存储:最后能将数据导入到一个用户能够使用的格式文件中以及为用户提供访问数据仓库的查询工具等。系统由多个数据源组成,而每个数据源可能是异构数据库、企业资源计划软件或其他应用程序等。采用任务共享的合作模式如WEB站点、送货系统、相关信息数据库和软件接口系统等。当从数据源系统中抽取数据时,应考虑到数据加载或周期性刷新加载以及部分软件接口编制和时间触发器响应等。数据仓库即数据综合层是一个规范化了的数据库,将来自所有数据源的数据集中在一个地方存储。当建立数据仓库时,主要问题是数据存储的灵活性,即必须满足第三范式。来自数据源系统的数据如果存在格式违规、参照完整性违规、交叉系统匹配违规以及内部一致性违规等现象时,应予以清除。数据仓库是一个用户不能访问的数据库,最终用户只能从数据集市或高性能查询结构中查询数据。数据仓库的数据是通过数据抽取和加载程序集进入数据集市的。数据集市是为支持最终用户查询而专门设计的数据库和数据结构(在本系统中,采用的是Oracle9i数据库)。当数据存储在关系型数据库时,星型模式是数据集市设计的标准方法。数据集市是数据结构的集合,按一定的格式组织以便于访问。使用查询工具(如Developer/2000,VB,VC++等)、数据挖掘技术、OLAP分析工具等从数据集市中抽取数据并提供给最终用户。

图1 质量控制系统数据仓库、集市结构
数据挖掘是数据仓库解决方案的一个重要组成部分,所谓数据挖掘(也称为知识发现),指的是从大型数据库或数据仓库中提取人们感兴趣的信息(知识)。数据挖掘技术可以成为计算辅助质量控制的重要工具。
1.2 数据挖掘模型
数据挖掘的方法有关联法、聚类法和概念描述法等,常用的技术有决策树、遗传算法、神经网络、专家系统、模糊理论、贝叶斯理论、灰色理论和粗糙集等。
质量灰色预测数据挖掘是通过系统质量数据序列的提取,寻求系统发展规律和变化趋势,从而按照规律预测系统未来的行为,并根据系统未来的行为措施,确定相应的控制决策进行控制。其工作原理是:首先通过质量采样装置对输出质量矢量Y的行为数据进行采集、整理;再由预测装置建模,计算出以后若干步的预测值;最后比较目标,确定质量控制矢量U,使未来的输出质量矢量Y尽量接近质量目标矢量。
定义1 设Yi=[Yi(1),Yi(2),…,Yi(n)],(i=1,2,…,m)为输出分量的质量采样序列,其GM(1,1)响应式为
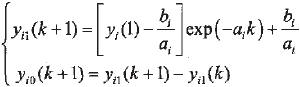 (1)
(1)
式中 Yi——时间响应函数
ai——参数列
bi——参数列
k——序数
若控制算子f满足
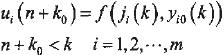 (2)
(2)
则称系统为质量灰色预测控制。
质量灰色关联分析系统是对一般控制系统附加质量灰色关联控制器而得的。它通过灰色关联度γ(J,Y)确定质量控制矢量U,从而使输出矢量与目标矢量的关联度不超出某一预定的范围。灰色关联分析实质上就是比较数据到曲线几何形状的接近程度,几何形状越接近,变化趋势也就越接近,关联度就越大。这样可从众多因素中提炼出影响系统的主要因素、主要特征和因素间对系统影响的差别等。
定义2 设Y=[y1,y2,…,ym]T为输出质量矢量,J=[j1,j2,…,jm]T为 目标质量矢量。若质量控制矢量U=[u1,u2,…,um]T中元素满足uk=fk(γ(J,Y));K=1,2,…,s。其中γ(J,Y)为输出质量矢量Y与目标质量矢量J的灰色关联度,则称系统为质量灰色关联控制。
关于灰色关联度γ(J,Y)的求法,常用方法有面积法和平均值法两种,多数情况下采用平均值法,即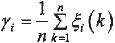 。这里给出质量灰色关联度系数
。这里给出质量灰色关联度系数
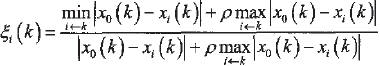
式中,P∈(0,+∞),称为质量分辨系数。P越小,分辨率越大。一般ρ的取值区间为[0,1],︱x0(k)-xi(k)︱称为第k个时刻质量指标x0与xk的绝对差。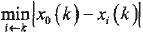 称为两极质量最小差,
称为两极质量最小差,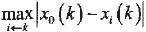 称为两极质量最大差。
称为两极质量最大差。
在一个质量信息数据库中,字段之间存在着各种各样的关系,这些关系就隐含在数据库所包含的数据中,挖掘关联规则的目的是找出这些隐含的关联。每条记录都有若干项构成,这些项称之为数据项(item)。设万T方为质数量据数据的集合,记为:T={t1,t2,…,tn}其中ti是质量记录数据,设I={i1,i2,…,in}是质量数据项集合,ij(1≤j≤n)是T中的一个质量数据项,每个ti是I的一个子集。每一个质量记录对应有一个标识符,称为TID。设X,Y属于I,且X∩Y=Φ,称X=>Y为一条关联规则。若规则在质量数据集T中成立,S称为规则X=>Y在质量数据集T中的支持度,C称为规则的置信度,也称为可信度。
定义3 S和C定义为如下

设定一个最小置信度minconf和一个最小支持度mmsup,则关联规则挖掘就是在质量数据库中找出所有置信度和支持度大于minconf和minsup值的规则。文献中有许多挖掘关联规则的算法,其中被广泛认可的是R. Agrawal等于1993年提出的Aprion算法。
1.3 基于灰色理论和关联规则数据挖掘质量控制方法的应用程序框图
根据式(1)~(5),编制了上述灰色理论和关联规则数据挖掘的质量控制计算机控制程序,其程序框图如图2、图3所示。
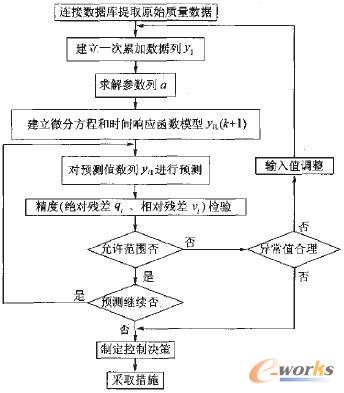
图2 质量灰色预测挖掘控制流程图
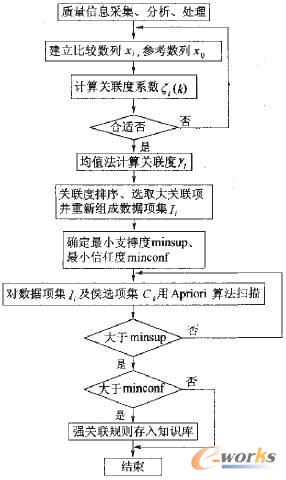
图3 质量灰色关联一关联规则数据挖掘控制流程图
2 应用实例
在某型号产品研制过程中,主要应设置的重点质量控制点有:质量评审与审核(包括合同评审、设计评审、工艺评审和质量评审等)、过程控制(包括元器件原材料代用、产品超差回用、新品试制控制、特殊过程工序以及过程追溯与标识等)、检验和试验(包括外购外协件入所复验、电子元器件老练筛选、试验设备检测、过程检验和例外放行记录)等。针对型号任务重、外协件多和涉及面广月寺点应制定相关的质量控制文件。如元器件和零部件是构成组件、系统的基本单元,其性能的可靠性程度直接影响产品的质量。在某型号产品某次试验中,发射16条次出现82个故障,更换了28个元器件,原因是装机前没有对元器件进行老练筛选,从而出现元器件的早期失效、造成发射失败。电子元器件老练筛选主要包括高温贮存和功率老练筛选、环境应力筛选的温度循环筛选、密封筛选的液浸检漏筛选以及检漏筛选的外观检查筛选。往往这些筛选带有破坏性,能否在产品质量特性值产生之前,就能预测到这些产品的质量特性值,从而实现产品质量的超前控制。为此,本研究提出用数据挖掘技术实现电子元器件老练筛选质量超前控制。实现超前质量控制的关键在于运用预测技术对于产品质量特性值给出合乎一定精度要求的预测值。目前的预测技术、方法很多,如粗糙集理论、贝叶斯理论、神经网络和灰色理论等。其中以灰色预测技术较为适用于产品质量特性值的预测。假定在电子元器件老练筛选某次试验中,对电容器、半导体集成电路、晶体管和继电器共18059支进行了试验(1995年统计)。其中,电容13292支,半导体集成电路1504支,晶体管3075支,继电器188支,不合格率为15.50%。在1996年统计中,电子元器件老练筛选不合格率为14.58%;1997年统计为16.78%;1998年为15.58%;1999年为16.25%,现要求预测老练筛选发展情况。主要实施步骤如下:对数据库中的电子元器件老练筛选信息表中筛选合格数和筛选不合格数以一定时间单位进行连续不间断检测,如历年来统计的不合格率数值,得产品质量特性原始数据列y,即y=[15.50,14.58,16.78,15.58,16.25]。根据原始数列y建立一次累加数据列Y1,即y1=[15.50,30.08,46.85,62.44,78.69]。然后按最小二乘法求解参数列a以及建立一次累加数据列y,的微分方程模型GM(1,1)和时间响应函数模型,得出y1(k+1)=901.74 exp(0.0172 k)-886.24,其具体结果见表1。
表1 电子元器件老练筛选质量预测分析
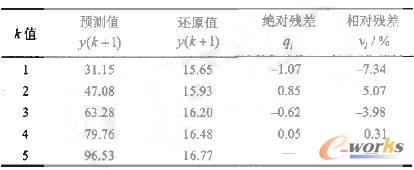
由表1可见预测精度较好,所以预测下一年的电子元器件老练筛选不合格率为16.77%。灰色预测超前质量控制在产品质量特性异常值出现之前就事先预NH到它的出现,并采取措施进行预防和避免。如在实际工作中尽可能选用成熟元器件和标准件,压缩元器件品种;进行降额设计,包括电压、电流、温升和功率等;进行热设计、防止散热不良导致失效;进行参数设计和容差分析,防止漂移失效等。本实例开发工具为Developer/2000,数据库为Oracle9i,数据库中除含有电子元器件老练筛选外,还包括外购外协件入所复验、元器件原材料代用、产品超差回用、新品试制控制、特殊过程工序以及过程追溯与标识等。
对一个产品或系统而言,质量问题的故障模式不是唯一的。这里分析的与该型号产品动力系统关系密切的主要有四个,即点火失败、点燃未交迭、过早停车和航速不正常。质量问题的发现,大部分万方数据是来自于可靠性试验。目前可靠性数据主要从现场试验中获取,然后进行合理处理,作为故障诊断与质量问题分析的数据。故障模式库是质量信息库中的关键库之一,对于故障现象进行归类整理形成的故障模式是企业的宝贵资源。在某型号发动机故障与质量问题分析系统中,采用灰色关联一关联规则分析用于发现故障信息间内在的联系,挖掘设备故障的产生原因(知识),对发动机运行状况进行诊断分析预测。针对该过早停车质量问题事件,采集故障信号,建立故障事物数据库,其中故障事物中的项按顺序存放。其中,xi(i=0,1,…,9)表示从过早停车质量故障问题事件中抽取出的几个不同的项,x0表示发动机工作不正常,x1表示冷却系统故障,x2表示内外轴密封件失效,x3表示配气阀座、阀衬碎裂,x4表示小滚轮轴断裂,x5表示燃烧室工作不正常,Xs表示轴承咬死,x7表示活塞咬死,x:表示大滚轮碎裂,x9表示螺母松脱,其中只要x1~x9任一项发生,都将导致x0发动机工作不正常。以xu为参考列,x1~x9为比较列,以每次实航试验数据为依据,取ρ=0.5,分别计算出ζi(i=1,…,9)和γi(i=1,…,9),得出γ1>γ4>γ2>γ3>γ5>γ6>γ9>γ7>γ8,令取γ=0.380,γ∈[0,1],然后对γi取γ截集,即去掉那些关联度γi>γ的数据项。取前5项(即γ1、γ4、γ2、γ3、γ5对应的项x1、x4、x2、x3、x5)作关联规则中的数据项,作关联规则分析,再重新组合后,其中I1←x1、I2←x4、13←x2I4←x3、I5←x5,如表2所示。
表2 过早停车质量故障数据库(部分)
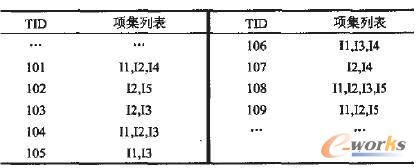
由表2可见,I1~I5表示经重新组合后再从质量故障事物中选取出的5个不同的项。假设最小支持度计数为2, 选取其中9个事物记录, 即tninsup=2/9,采用Apriori算法,找出支持度大于minsup的所有频萦数据项集;反复扫描数据库,采用项的连接关系生成关联规则。在生成关联规则的过程中,采用了项集剪枝技术,剪枝原则是:频繁项集的所有子集都是频繁的。例如当L2中{I2,I3}和{I3,I5}连接生成一个候选项集{I2,I3,I5}时,由于它的一个子集{I2,I5}不属于L2,因此将{I2,I3,I5}不存放到候选项集C3中。以项集{I2,I3,I4}为例给出关联规则,由于此项集的非空子集有{I2,I3},{I2,I4},{I3,I4},{I2},{I3},{I4},结果关联规则如下:I2 and I3=>I4,confidence=50%;I2 and I4=>I3,confidence=50%;I3 and I4=>I2,confidence=50%;I2 =>I3 and I4,confidence=33%;I3 =>I2 and I4,confidence=28%;I4 =>I2 and I3,confidence=33%。将minconf设置为50%,则只有前3个规则有效,并认为是强规则。将这些规则存入知识库中,构造故障诊断与质量问题分析模型,以便于决策、评价和采取措施等。
3 结 论
基于数据仓库和数据集市的数据挖掘是一个新兴而有实用价值的研究领域,有着广阔的前景。提出通过数据挖掘技术——灰色理论和关联规则挖掘技术从质量数据信息库中自动获取有关信息和知识、规则,以支持质量控制,对计算机辅助质量控制系统设计与开发的研究做了有益的探索。把数据挖掘技术引入产品质量控制领域是一个较新的尝试,具有重要的意义。
本文作者:方喜峰 赵良才 吴洪涛 来源:万方数据
CIO之家 www.ciozj.com 微信公众号:imciow